很多人以为 Grok Imagine 里的 Speed 和 Quality,区别就是”一个快一慢”。如果你也这么想,那大概率在白白浪费配额,还顺便牺牲了画质。
真相是:这两个模式跑的是同一个 Aurora 模型,它们的差异不在”模型”,而在一个你看不见的参数——去噪步数(denoising steps)。
而这一个参数,像多米诺骨牌一样,同时决定了三件事:画质、配额消耗、甚至出图能不能过审。
这篇文章,我想把这条因果链完整地拆给你看。
先看下面两组不同 Mode 的对比图

Prompt:
A cinematic editorial fashion portrait, a young woman in an oversized
camel wool coat over a fine silk slip dress, standing on a quiet
European city street at dusk. Behind her, a vintage atelier storefront
with gold serif lettering reading “MAISON LUMIÈRE” above the window,
its warm light spilling onto wet cobblestones. Diffused cool overcast
light blending with the warm shopfront glow, soft near-shadowless
illumination, shallow depth of field, wide-angle lens with exaggerated
spatial depth. Muted earth tones — camel, taupe, soft gray, quiet
blue — desaturated editorial register. Subtle film grain, micro-specular
highlights on silk, photorealistic, Vogue editorial aesthetic.
Aspect ratio 9:16.
实测对比结论:
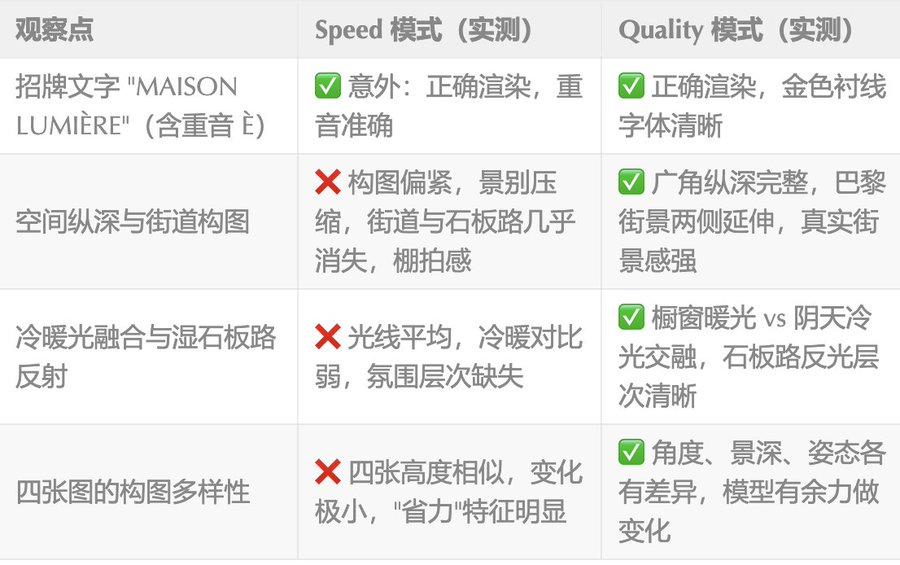
⚠️ 实测意外发现:原预期 Speed 会糊掉重音符号 È,但两个模式均正确渲染了 “MAISON LUMIÈRE”。说明 Aurora 的文字能力已大幅提升,文字渲染不再是两者的主要差距。真正的分水岭在空间构图与光影层次——去噪步数带来的价值,比文字渲染更深,也更难用肉眼事先预判。
一、先理解一件事:AI 出图是”从噪点里雕出来的”
扩散模型(diffusion model)生成一张图,不是一笔画出来的,而是从一团纯随机噪点开始,一步一步”去噪”,每一步都让画面更清晰一点,直到最后一张完整的图浮现出来。
这个”一步一步”,就是去噪步数。
步数越多,模型有越多机会去修正瑕疵、对齐文字排版、雕琢微观细节——代价是更慢、更耗算力。步数越少,出图越快,但模型来不及把每个细节都收拾干净。
理解了这一点,Speed 和 Quality 的一切区别,都顺理成章了。
Quality 模式:跑更多去噪步数。它会反复清理噪点、严格映射文字排版、把微观细节推到极限。基于 Aurora 的 MoE 架构,一次给你 4 张高保真图,在细节、光影、文字渲染上明显更强——代价是慢。
Speed 模式:步数固定且少,延续 Grok 一贯的”快速连续生成”风格。胜在迭代飞快,适合海选创意、批量铺图——代价是细节、文字、暗部这些”需要时间收拾”的地方会糊。
一句话:Speed 用来探路,Quality 用来定稿。
二、被忽略的代价:Quality 模式会让你的配额断崖式下跌
这是最多人踩的坑。
因为 Quality 模式跑的去噪步数多得多,它吃掉的 GPU 算力也多得多。而 SuperGrok 的限速器,会针对算力消耗来惩罚你的滚动配额窗口——有用户实测,开 Quality 模式时,可生成上限会从 150 张直接掉到 40 张左右。
注意这里有两个反直觉的点:
第一,它不是”每日固定额度”,而是滚动窗口。 你的可用生成量会根据你近期的活动量持续浮动,而不是每天清零重置一个固定数字。你最近用得猛,额度就缩水得快。
第二,每一次编辑都算一次全新生成。 笔刷修补、画布扩展(outpainting)、风格混合——你每对一张图应用一次修改提示词,Aurora 都当作一次全新请求来计费。举个例子:你生成 1 张底图,再做 5 次连续笔刷修手部,实际上你已经烧掉了 6 个名额,不是 1 个。
异形比例也会加重消耗:超宽 16:9、复杂竖版,再配上长描述,模型要干的活更多,配额掉得更快。
所以正确的省配额姿势是:先用 Speed 模式锁定构图和方案,确认满意了,再切到 Quality 模式做最终精修。 别一上来就开 Quality 反复试错,那是在拿你最贵的算力做最便宜的事。
三、一个有意思的观察:两个模式的”审核脾气”不一样
如果你认真用过 Grok 出图,可能注意到一个现象:同一段 prompt,在 Speed 和 Quality 两个模式下,过审结果有时不一样。
这不是玄学。两个模式的生成管线不同——去噪步数、中间产物、最终输出的清晰度都不一样——而审核系统同时看文本 prompt 和输出图像。当输出的”成熟度”和细节密度不同,触发审核分类器的方式自然也会有差异。
这是个值得创作者理解的平台机制,但它不是一个可以拿来钻空子的漏洞。真正稳妥的做法,从来不是去猜哪个模式审核更松,而是把你的创作意图明确地锚定在专业语境里。
这就引出最后一部分——也是对正经创作者最有用的一部分。
四、与其试探红线,不如重构你的语言
Grok 的审核确实比很多模型激进。做高定、时尚、艺术人像的创作者,经常被一刀切误伤——明明想做的是有张力的编辑大片,却被归进了风险类别。
被误伤,往往不是因为画面真的越界,而是因为你的 prompt 里某些模糊的、指向身体的描述,被模型关联到了错误的分类。
解法不是”怎么贴边不被发现”,而是把模型对你画面的理解,框死在时尚 / 艺术 / 编辑摄影的语境里:
- 用专业语汇开路:editorial fashion photography、fine art portraiture、haute couture、Vogue cover aesthetic、具名摄影师风格。
- 把描述重心放在面料、廓形、光影、构图、品牌调性上,而不是模糊的身体描写。做内衣产品图、泳装海报时尤其如此——讲丝绸的流动、亮片的反光、剪裁的结构,比讲身体本身既更容易过审,出图质量也更高。
- 给画面一个明确的”职业身份”:它是一张杂志封面、一组品牌提案、一帧时装秀后台——当模型知道这是”什么类型的图”,它的判断会稳定得多。
这套思路的本质是:你不是在和审核系统博弈,你是在帮模型正确理解你的专业意图。 而这恰好也是更高级的 prompt 工程——精确的语境,永远比模糊的试探产出更好的结果。
写在最后
Speed 和 Quality,本质是同一个模型在”去噪步数”上的一次取舍。这次取舍,决定了你的画质、你的配额、甚至你的图能不能落地。
所以正确的工作流式流是:
- 用 Speed 探路、
- 用 Quality 定稿、
- 用专业语言锚定意图